How should rule results be stored? - JSON vs Structures¶
Note
While Jackson is faster than circe serialization for JSON it doens't serialize easily so only used for comparison as its the fastest possible serialization framework.
UDF Created Structures¶
When serializing rule results to Nested Rows via UDF struct creation (shown as Orange) the results are very expensive, the more complex the rule setup the worse the performance. In comparison Jackson (shown as blue) keeps a low cost as it's just a string (the cost instead is in parsing, storage and filtering)
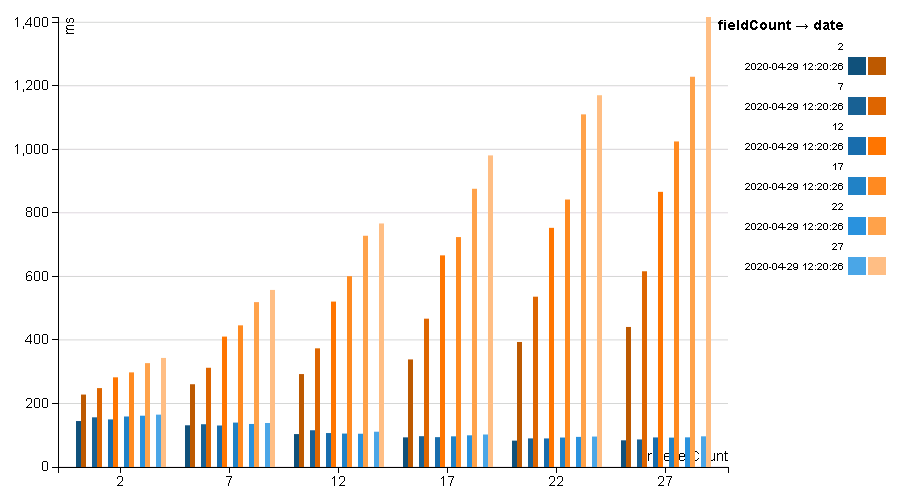
Expression Created Structures¶
When serializing rule results with a custom Expression (shown as orange, using eval only - without custom compilation), Jackson (shown as blue) based serialisation looses it's clear lead with Expressions closing the gap as complexity increases:
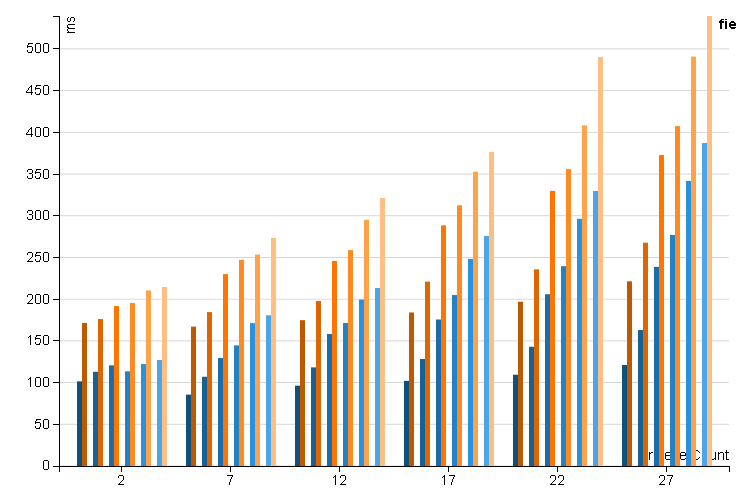
Filtering Costs¶
Filtering on a nested column with deep queries (shown in red) is as expected faster the same query with a json structure. Nested predicates can be pushed down to the underlying storage for efficient querying.
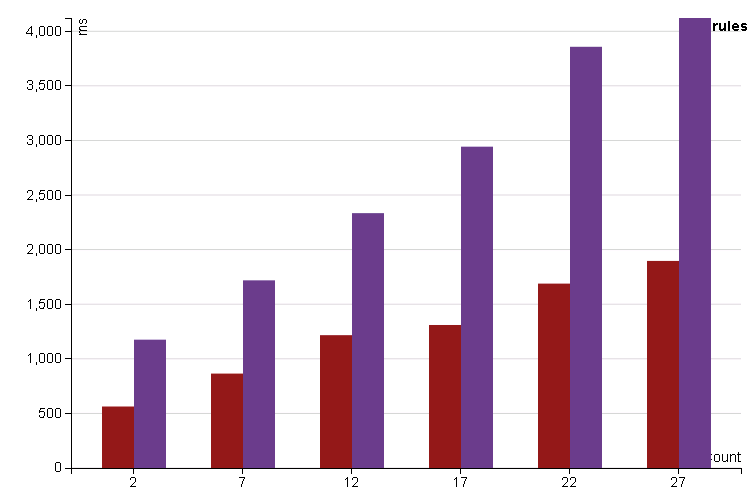
Note
Depending on the Databricks runtime used the benefit from seperating the overallResult field to a top level field can be 10-20% faster. While each new release of Spark and DBR closes this gap it is recommended to use addOverallResultsAndDetailsF to split the fields.
This not only improves filter speed but also benefits with a simpler filter sql.
Structure Model - storage costs¶
A naive structure representing RuleSuite, RuleSet and Rule results is actually less efficient than storage of JSON, however the current compressed model used by Quality has low overhead for even complex results.
Created: April 22, 2024 08:24:32